Apoorva BeeduI am a Sr. AI Research Engineer at Rivian VW Tech. I got my PhD at Georgia Institute of Technology where I worked on Video and Language Understanding and was advised by Dr. Irfan Essa and Dr. Justin Romberg. My research interests are primarily focused on understanding video through the usage of Language cues for various tasks like summarization, action anticipation etc., and have previously worked on 6D object pose estimation and human activity recognition. Broadly, my research is in the union of
During the summer of 2021, I was an intern at Facebook Reality Labs, collaborating with Chengde Wan and Robert Wang. In 2020, I undertook an internship at Microsoft Research with Dr. Amol Ambadekar. In the summers of '18 and '17, I interned at a startup called NodeIn, working with Dr. Suresh Kannan. Prior to joining Georgia Institute of Technology, I spent a year at Asteria Aerospace Limited as a software Engineer. Email: apoorvabeedu [at] gmail [dot] com GitHub / Google Scholar / LinkedIn / CV |

|
News
Show earlier news
|
ResearchI'm interested in computer vision, machine learning, video analysis and multi-modal representations. |

|
HierSum: A Global and Local Attention Mechanism for Video SummarizationApoorva Beedu, Irfan Essa CVPR 2026 workshop on Vision Intelligence for Real-world Challenges pdf / bibtex / A hierarchical attention mechanism for instructional video summarization that combines fine-grained local cues from subtitles with global context from video-level instructions, using the “most replayed” statistic as supervision to identify the most important segments. |
|
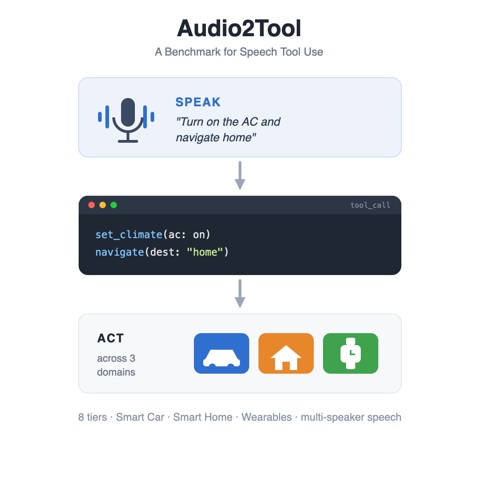
Audio2Tool: Speak, Call, Act – A Dataset for Benchmarking Speech Tool UseRamit Pahwa*, Apoorva Beedu*, Parivesh Priye, Rutu Gandhi, Saloni Takawale, Aruna Baijal, Zengli Yan Interspeech 2026 pdf / bibtex / project page / A dataset for benchmarking speech tool use, spanning eight tiers of spoken commands from direct calls to multi-turn conversations and multi-speaker intent blending across smart car, smart home, and wearable domains. Dataset available on Hugging Face. |
|
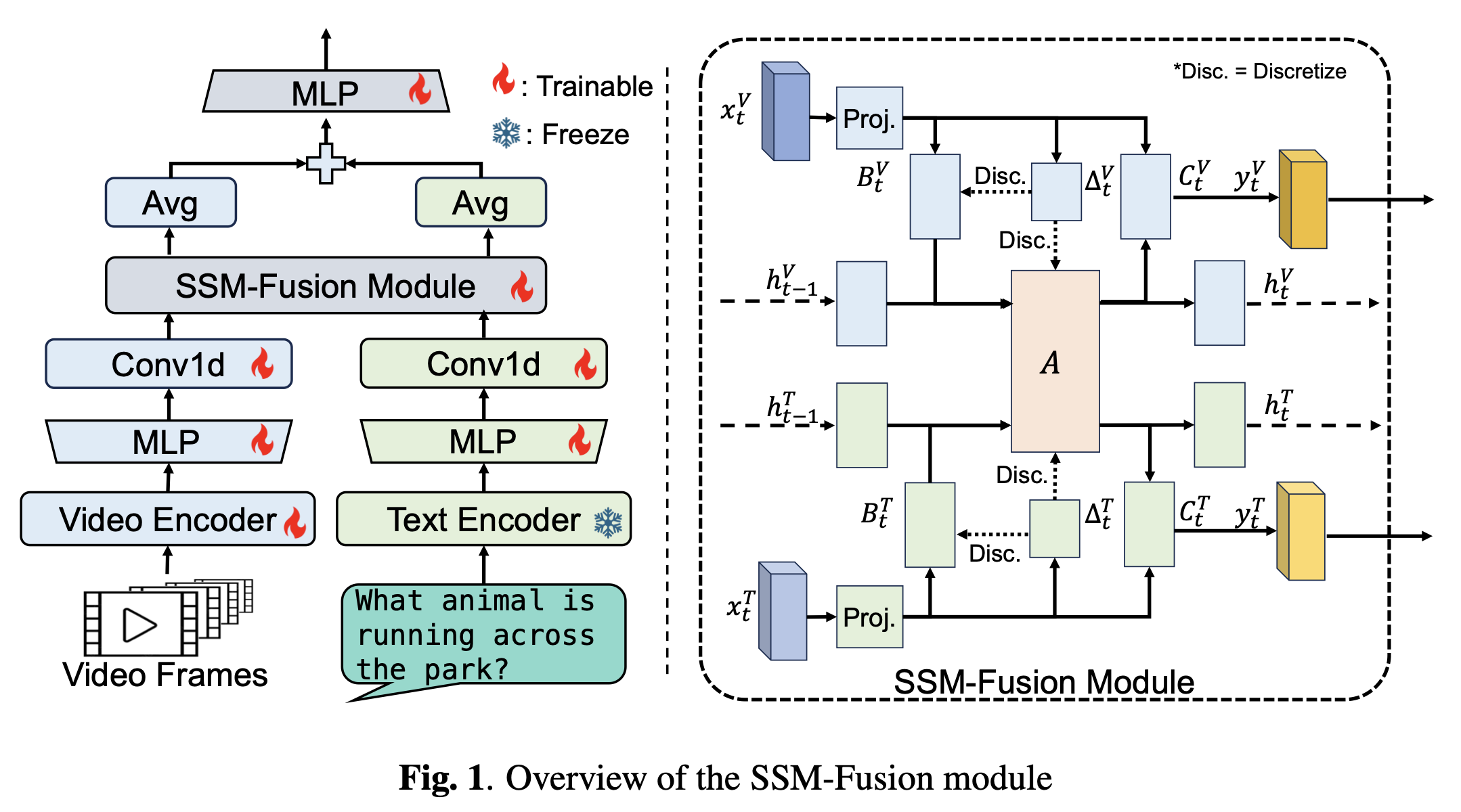
Mamba Fusion: Learning Actions Through QuestioningApoorva Beedu*, Zhikang Dong*, Jason Sheinkopf, Irfan Essa ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) pdf / code / bibtex / project page / We introduce MambaVL, an efficient mamba based fusion method for vision language models. |
|
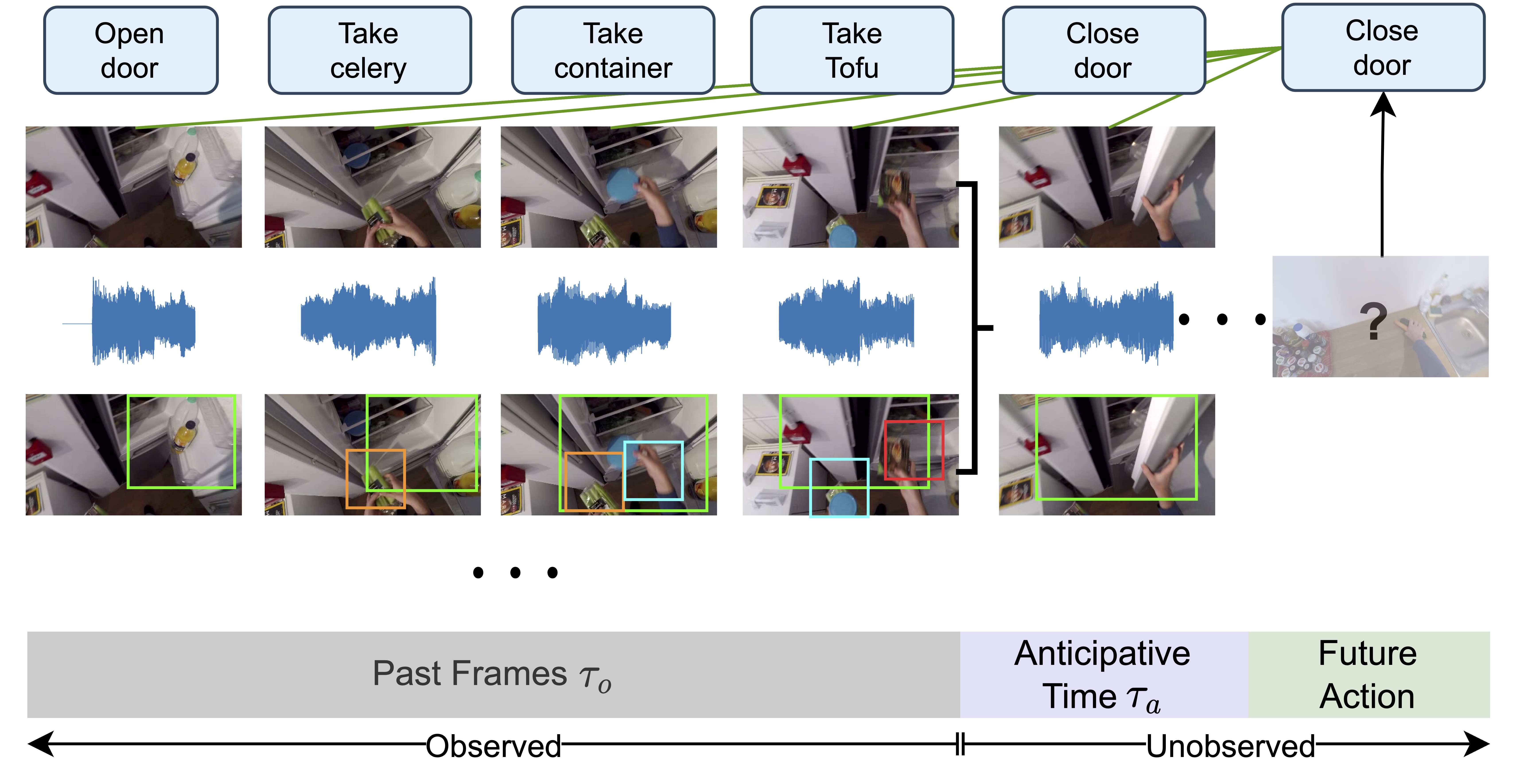
Text Descriptions of Actions and Objects Improve Action AnticipationApoorva Beedu, Harish Haresamudram, Irfan Essa ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) pdf / bibtex / project page / supp / Introduces contrastive learning for Action Anticipation and evaluates using text data as additional modalities. Detailed technical report can be found here |
|
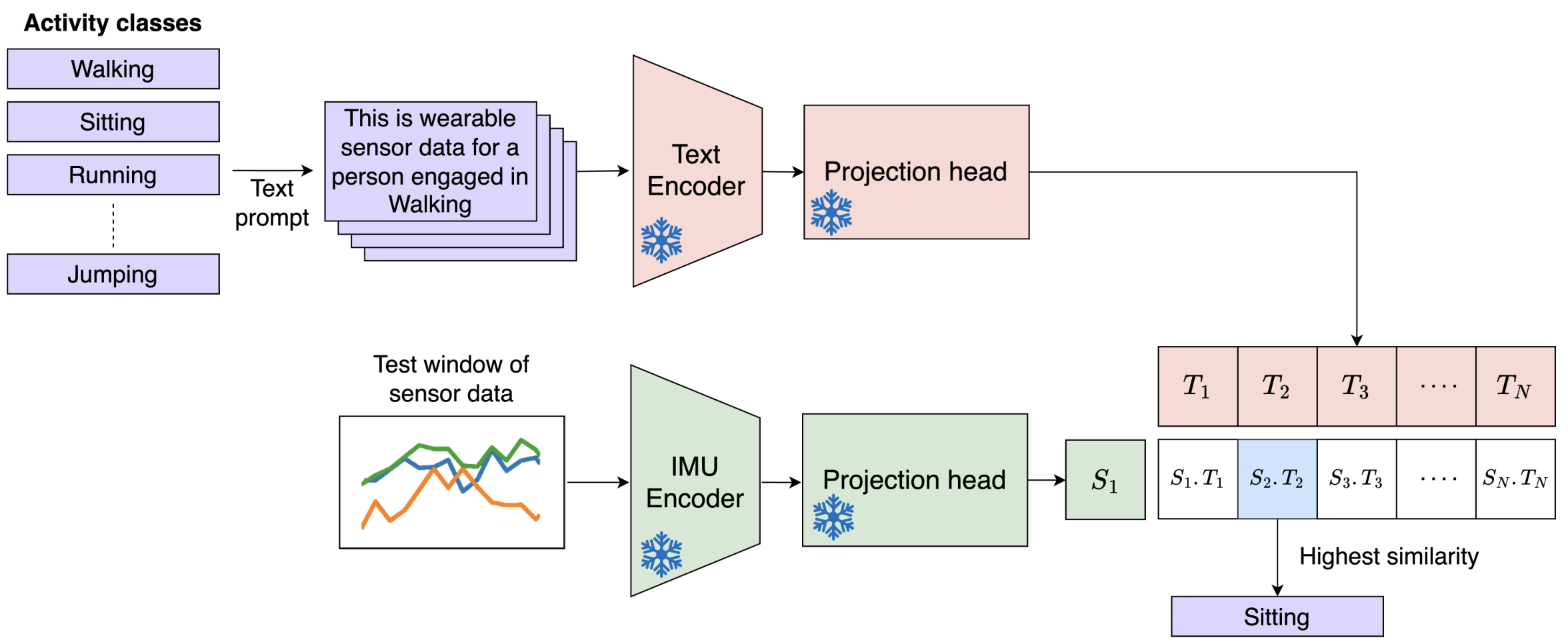
Limitations in Employing Natural Language Supervision for Sensor-Based Human Activity Recognition--And Ways to Overcome ThemHarish Haresamudram, Apoorva Beedu, Mashfiqui Rabbi, Sankalita Saha, Irfan Essa, Thomas Ploetz Proceedings of the AAAI Conference on Artificial Intelligence 2025 pdf / bibtex / project page / We investigate whether natural language supervision can be used for wearable sensor based Human Activity Recognition (HAR), and discover that surprisingly it performs substantially worse than standard end-to-end training and selfsupervision. |
|
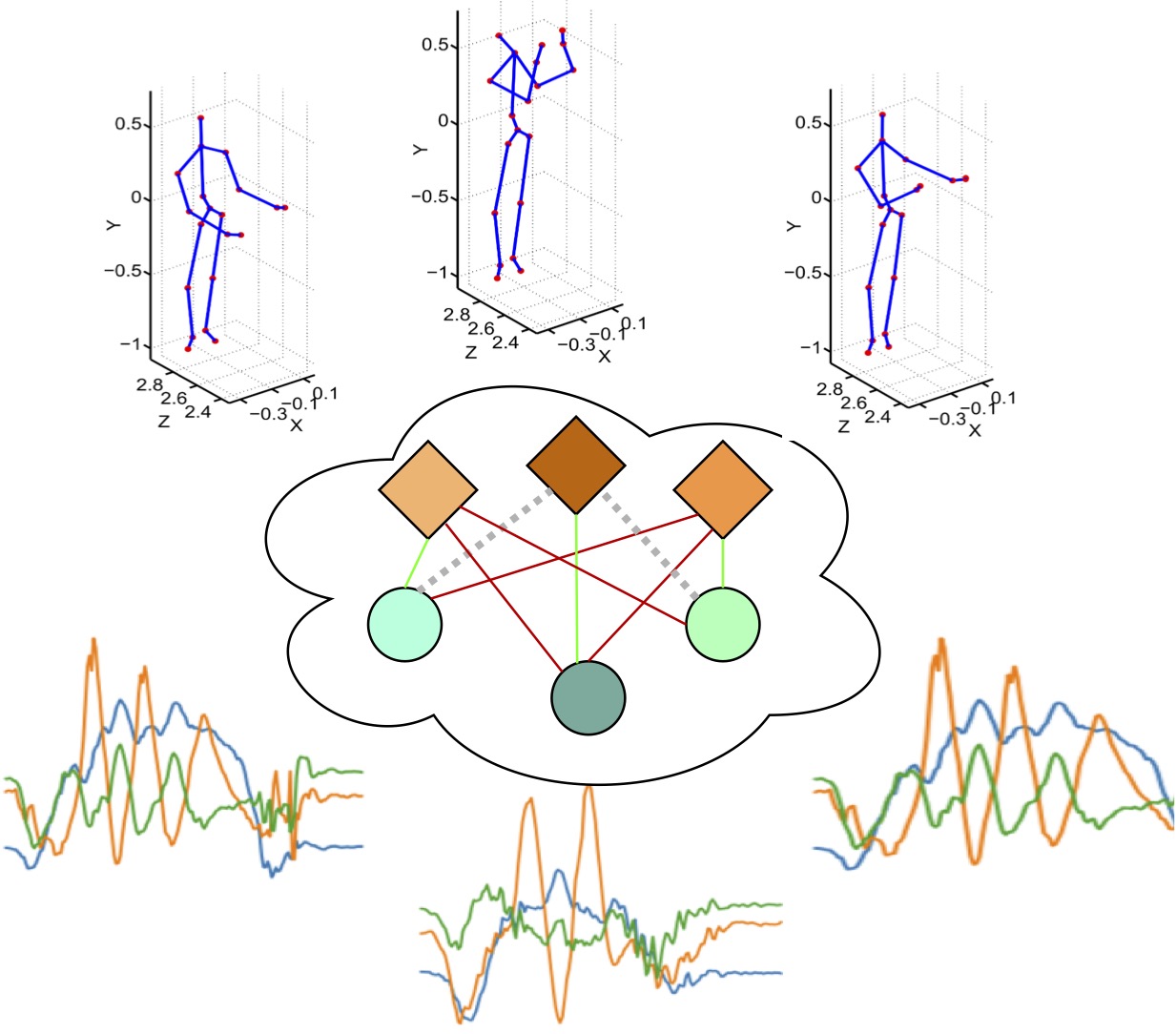
Multimodal Contrastive Learning with Hard Negative Sampling for Human Activity RecognitionHyeongju Choi, Apoorva Beedu, Irfan Essa ICCV 2023 workshop on PerDream: PERception, Decision making and REAsoning through Multimodal foundational modeling pdf / bibtex / Introduces contrastive learning with hard negative sampling for Human Activity Recognition. |
|
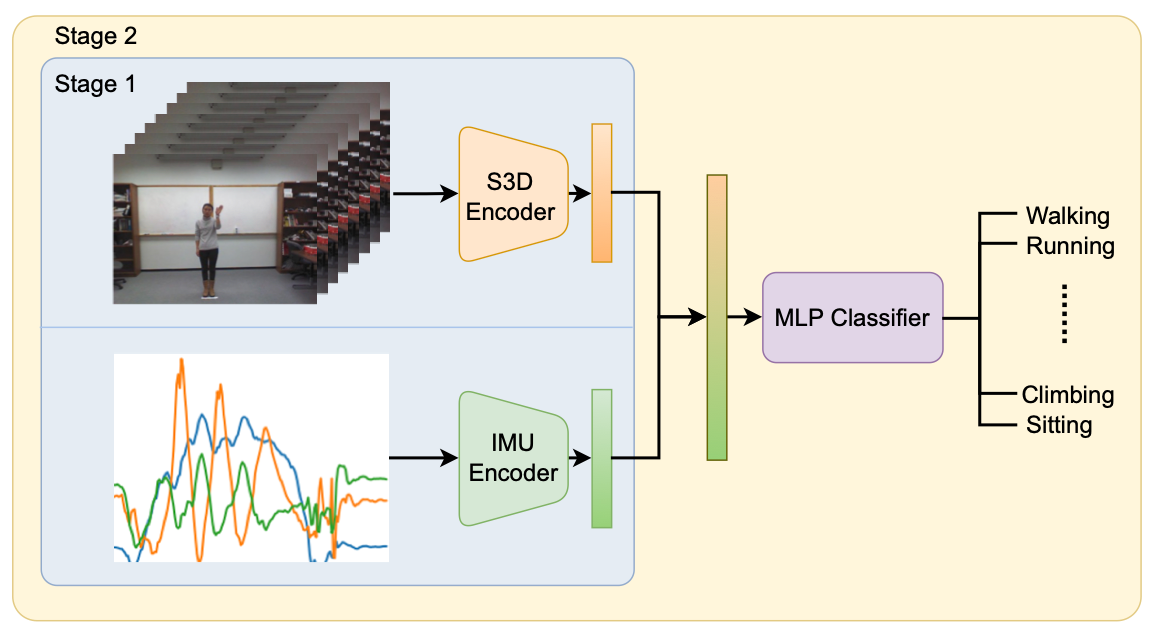
Multi-Stage Based Feature Fusion of Multi-Modal Data for Human Activity RecognitionHyeongju Choi, Apoorva Beedu, Harish Haresamudram, Irfan Essa ArXiv preprint, 2022 pdf / bibtex / We present a multi-modal framework that learns to effectively combine features from RGB Video and IMU sensors for Human Activity Recognition. |
|
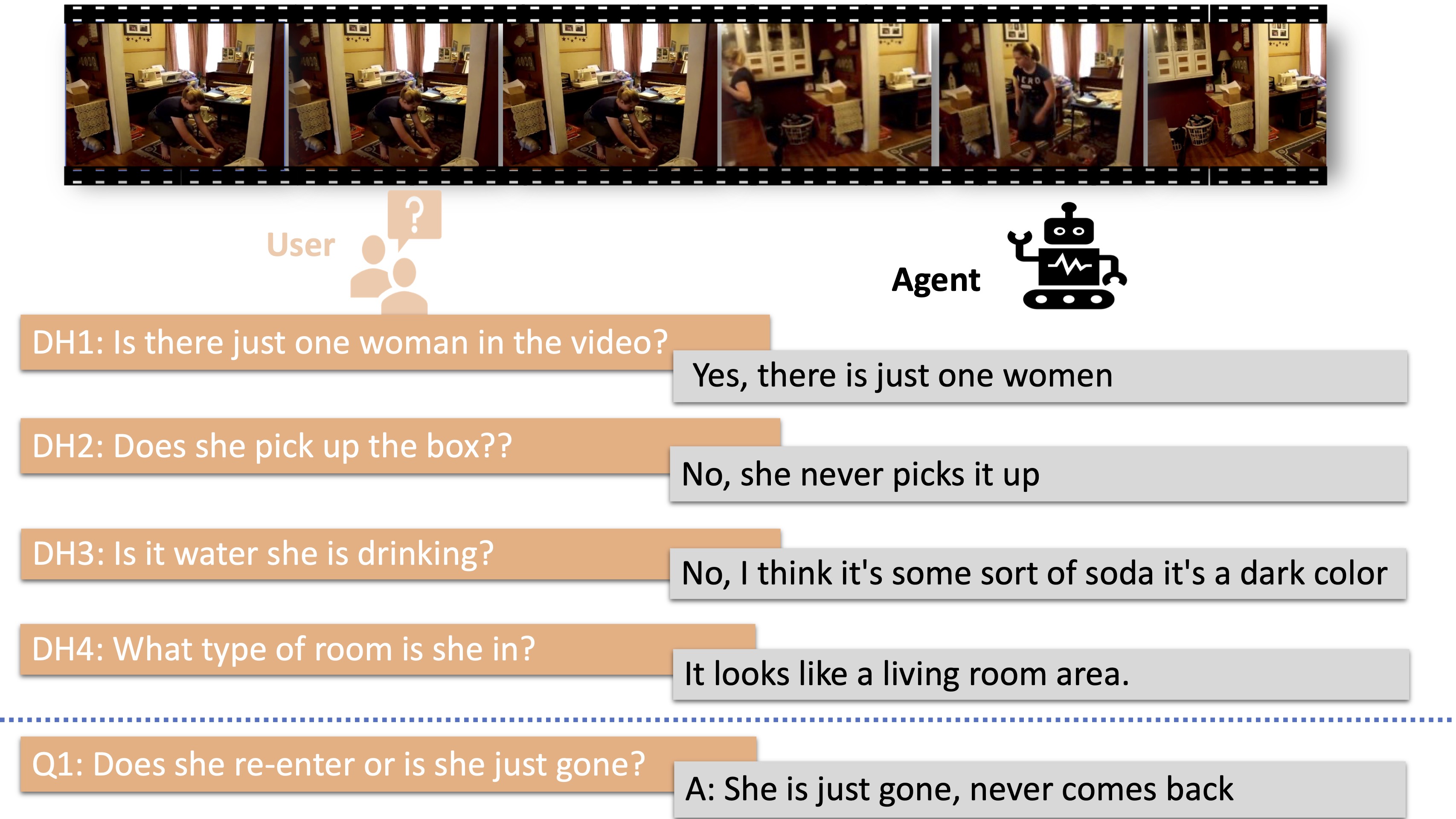
End-to-End Multimodal Representation Learning for Video DialogHuda Alamri, Anthony Bilic, Michael Hu, Apoorva Beedu, Irfan Essa NeurIPS 2022 workshop on Vision Transformers: Theory and Applications pdf / bibtex / We present a framework for video based dialog task. |

|
Video based Object 6D Pose Estimation using TransformersApoorva Beedu, Huda Alamri, Irfan Essa NeurIPS 2022 workshop on Vision Transformers: Theory and Applications pdf / code / bibtex / We introduce a Transformer based 6D Object Pose Estimation framework VideoPose, comprising an end-to-end attention based modelling architecture, that attends to previous frames in order to estimate accurate 6D Object Poses in videos. |
|
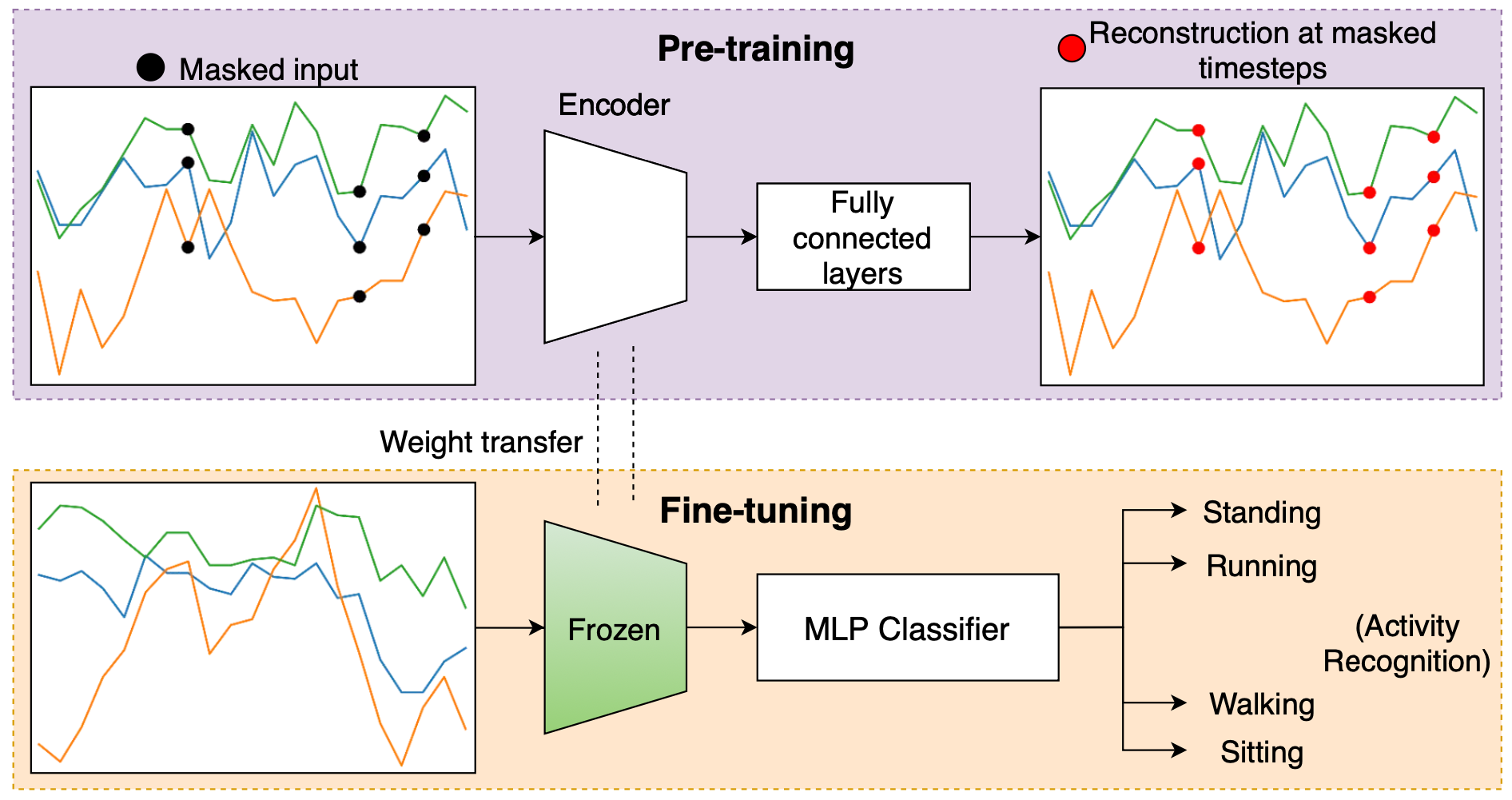
Masked reconstruction based self-supervision for human activity recognitionHarish Haresamudram,Apoorva Beedu, Varun Agrawal, Patrick L Grady, Irfan Essa, Judy Hoffman, Thomas Plötz Proceedings of the 2020 ACM International Symposium on Wearable Computers pdf / bibtex / We introduce masked reconstruction as a viable self-supervised pre-training objective for human activity recognition and explore its effectiveness in comparison to state-of-the-art unsupervised learning techniques. |
|
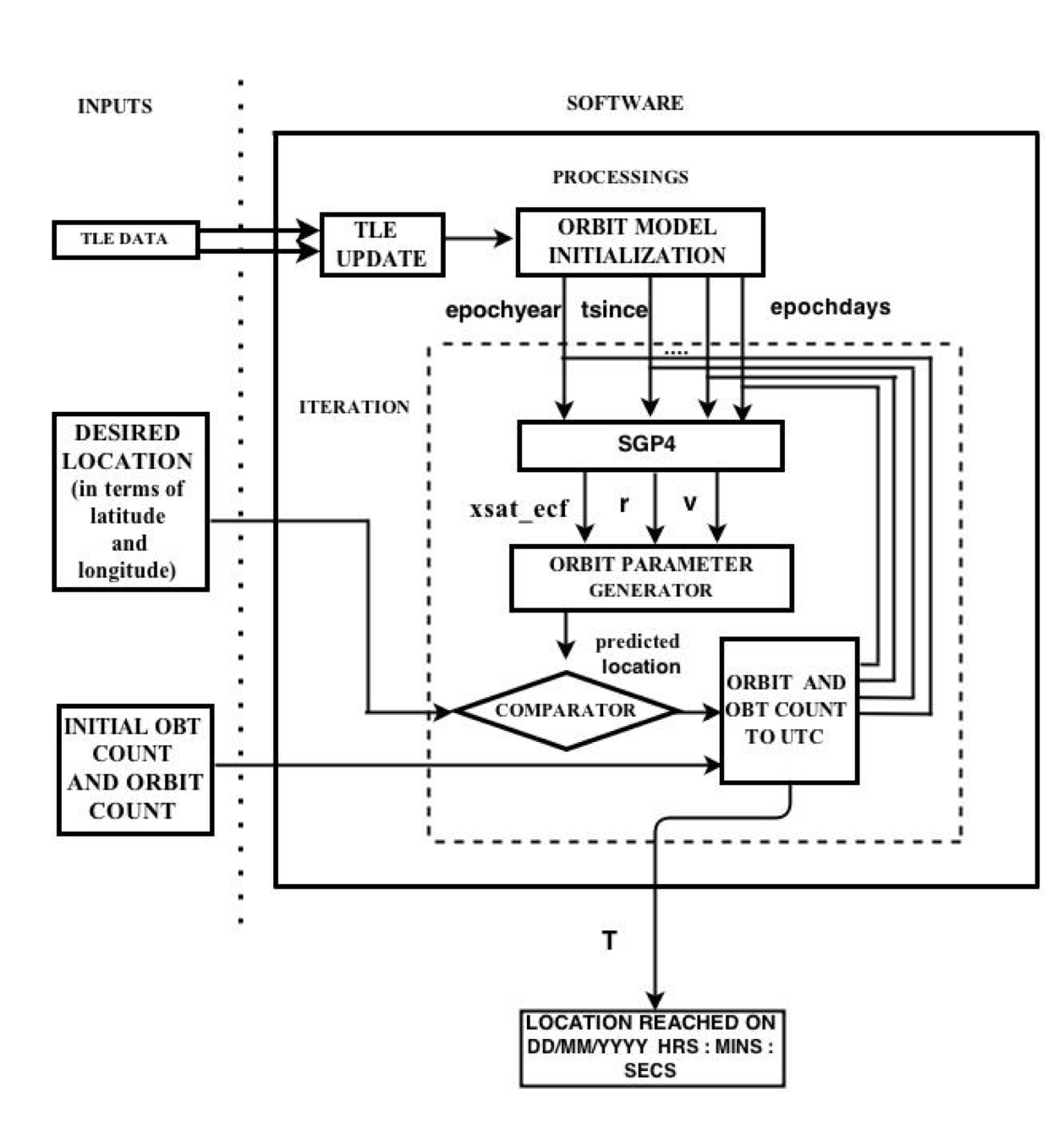
Location based payload imagingApoorva, J and Mohan, Brinda and Beedu, Apoorva and Nayak, Mahendra M and Rao, Divya and Agrawal, VK 2015 IEEE International Conference on Electronics, Computing and Communication Technologies (CONECCT) pdf / bibtex / We present a method to add the capability of imaging at any commanded latitude and longitude by including a provision to estimate the time required to reach the desired latitude and longitude using Location-Based Payload Imaging. |
Teaching
|
ServiceI have reviewed for BMVC(2021-2024), PerDream2023, VTTA2022. |
Mentoring
|
|
Design and source code from Jon Barron's website |